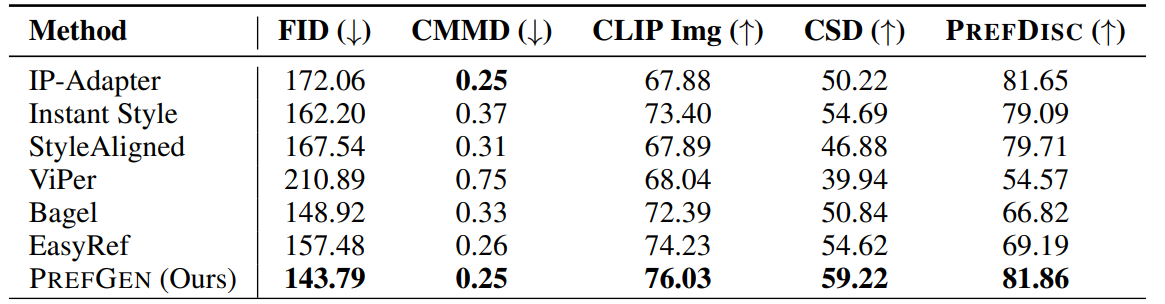
Method
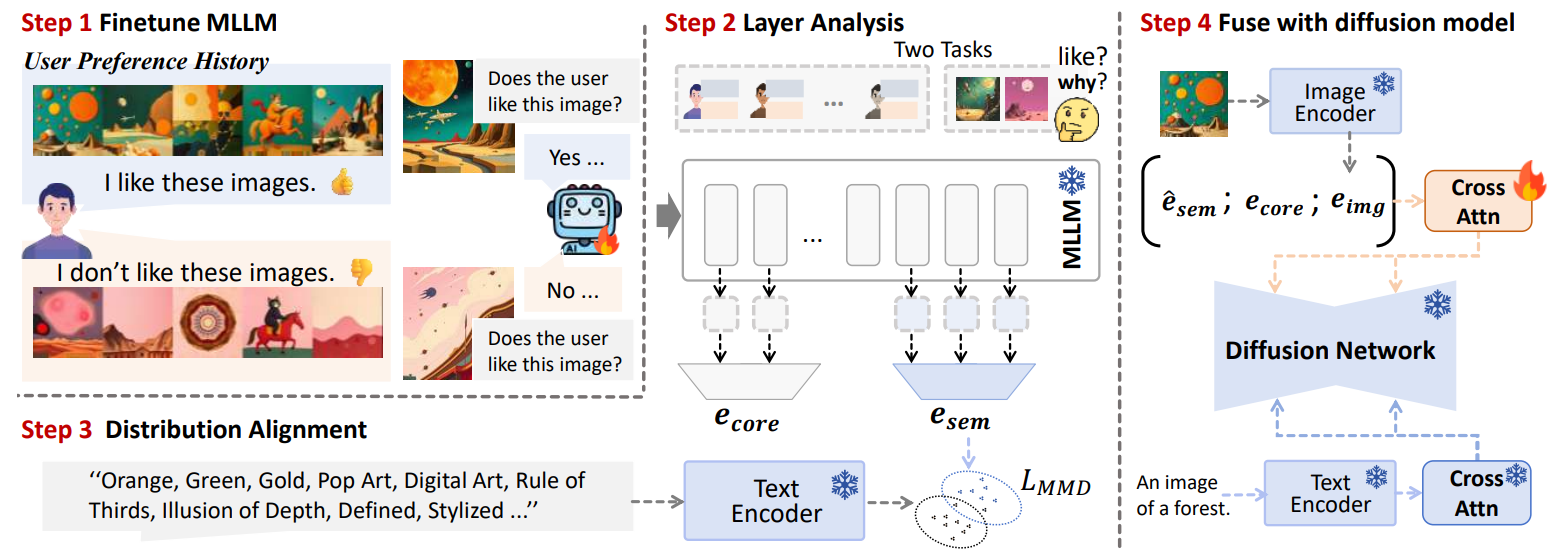
Figure 1: Overview of our MLLM-based preference learning framework.
- MLLM training: Fine-tune an MLLM on a preference-oriented VQA dataset — this helps the model learn multi-image preference reasoning.
- Layer probing & embedding extraction:
esem: extracted from the top 4 layers (last-token pooling) — captures like/dislike semantics and styles used for aligning to text space.ecore: middle-to-upper layer embeddings — capture stable user identity signals that generalize across prompts.
- Distribution alignment: Map
esemthrough a small MLP and minimize MMD against paired CLIP text embeddings (attributes). Distribution-level loss preserves diversity and avoids collapse that point-wise losses can cause. - Fusion & conditioning: Form final user vector
e_u = [ĕsem; ecore; eimg], whereeimgis a CLIP image embedding from a liked example. Inject into the diffusion UNet via a parallel user cross-attention branch.